
第三章 程序的机器级表示
历史
- Intel 1985 IA32
- AMD 2003 x86-64 (amd64)
机器级代码
对于机器级编程,重要的两个抽象:
- 指令级架构
- 虚拟地址
在编译过程稿,编译器会完成大部分工作,将把用C语言提供的相对比较抽象的执行模型表示的程序转化成处理器执行的非常基本的指令。
汇编与机器代码的二进制相比,主要特点是它用可读性更好的文本格式表示。
- PC - x86-64中用 `%rip% 表示
- 整数寄存器 - 包含16个命名的位置,分别存储64位的值。有的存放地址或整数数据,有的用来记录重要的程序状态。其他寄存器用来保存临时数据,例如过程参数和局部变量,以及函数的返回值。
- 条件码寄存器 - 保存着最近执行的算数或逻辑指令的状态信息,用来实现控制或数据流中的条件变化,例如 if 和 while
- 向量寄存器 - 存放一个或多个整数或浮点数的值
程序内存
- 程序的可执行机器代码
- 操作系统需要的信息
- 用来管理过程调用和返回的运行时栈
- 用户分配的内存块
程序内存用虚拟内存来寻址,在任意给定的时刻,只有有限的一部分虚拟地址被认为是合法的。 例:x86-64的虚拟地址由64位的字来表示,在目前的实现中,这些地址的高16位必须被设置为0,所以地址实际上能指定的是2^48或256TB范围内的一个字节。
机器执行的程序只是一个字节序列,它是对一系列指令的编码, 机器对产生这些指令的源代码几乎一无所知。
数据格式
字 表示 16位数据类型 32位 双字 64位 四字
访问信息
CPU 包含一组 16个存储 64位值得 通用目的寄存器 用来存储整数类型和指针
这些寄存器都以 %r 开头
- 8086 有 8个 16位寄存器 标号
%ax ~ %sp% - IA32 有 8个 32位寄存器 标号
%eax ~ esp% - x86-64 原 8个寄存器拓展为 64位 标号
%rax ~ %rsp,增加8个64位寄存器,标号%r8 ~ %r15

栈指针 %rsp 指明运行时栈的结束位置。
生成小于8字节结果的指令,有两条规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节数字的指令会把高位的4个字节置为0
操作数指令符
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。
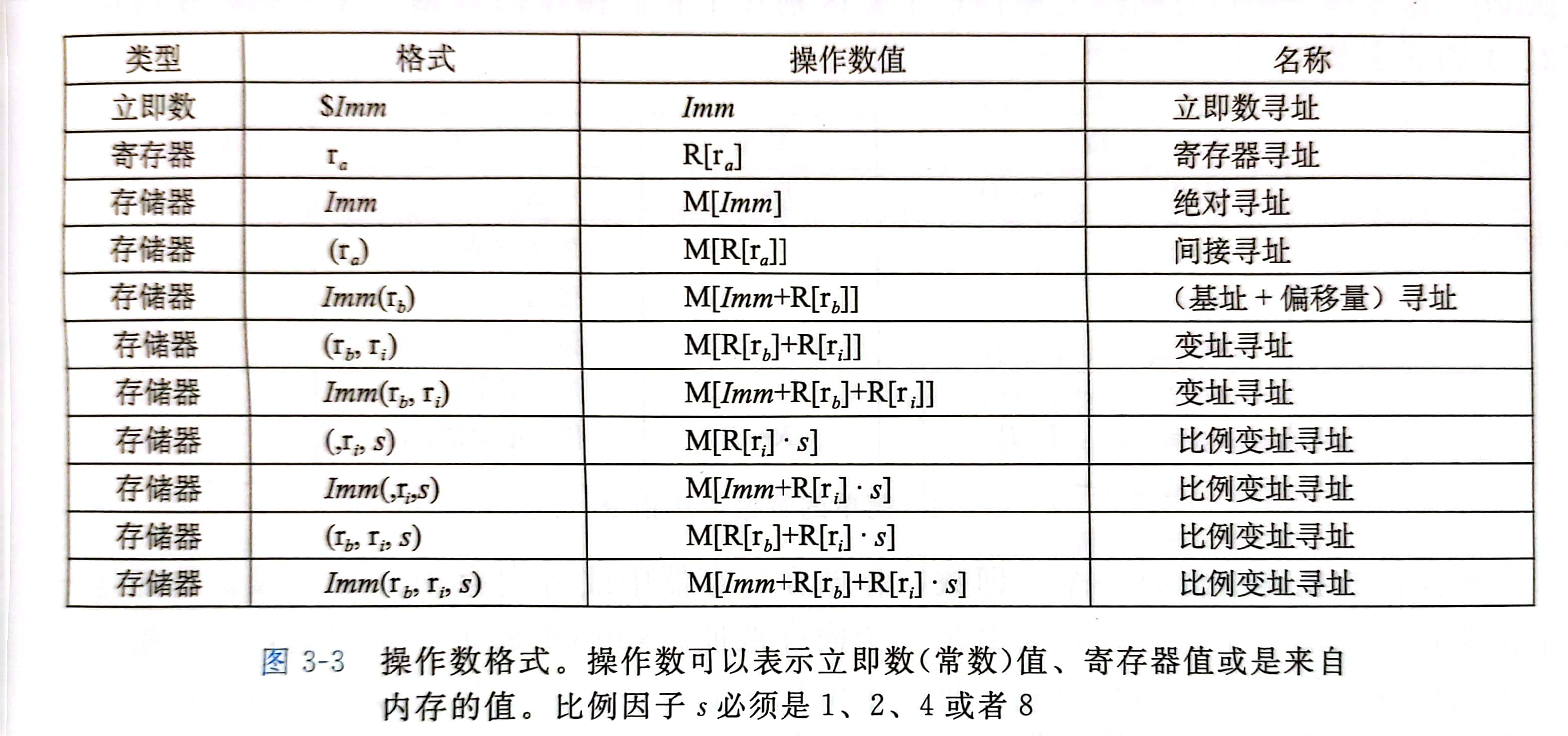
操作数被分为三种
- 立即数
表示常数值,立即数的书写方法是
$后面跟一个标准C表示法表示的整数 - 寄存器 表示整个寄存器的内容,将寄存器集合看成数组 R ,用寄存器标识符作为索引 用 r_a 表示任意寄存器 a ,使用引用 R[r_a] 表示它的值
这四个数据寄存器都是16位的,实际由两个8位寄存器组合而成,这是为了灵活处理8位数据。每个寄存器可以将高、低8位分别作为独立的8位寄存器使用。其中的高8位用AH、BH、CH、DH表示,低8位用AL、BL、CL、DL表示。 AX 寄存器称为累加器,常用于存放算术、逻辑运算中的操作数或结果。另外,所有的I/O指令都要使用累加器与外设接口传递数据。 BX 寄存器称为基址寄存器,常用来存放访问内存时的地址。 CX 寄存器称为计数寄存器,在循环、串操作指令中用作计数器。 DX 寄存器称为数据寄存器,在寄存器间接寻址中的I/O指令中存放I/O端口的地址。 此外,在做双字长乘除法运算时,DX 与AX合起来存放一个双字长数(32位),其中DX存放高16位,AX存放低16位。
- 内存引用
会根据计算出来的地址 (有效地址) 访问某个内存位置
有多种不同的
寻址模式,允许不同形式的内存引用 表格底部表示的是最常用的形: - 立即数偏移 Imm
- 基址寄存器 r_b 必须是64位寄存器
- 变址寄存器 r_i 必须是64位寄存器
- 比例因子 s 必须为 1、2、4 或 8 有效地址计算通用形式: Imm + R[r_b] + R[r_i] * s
其他形式是这种通用形式的特殊情况
数据传送指令
将数据从一个位置复制到另一个位置的指令
下文将不同的指令划分成 指令类
MOV类
最简单的数据传送指令 由四条指令组成,这些指令执行一样的操作,区别在于操作的数据大小不同
- movb 1byte
- movw 2byte
- movl 4byte
- movq 8byte
 MOV 指令只会更新目的操作数指定的那些寄存器字节或内存位置
注:常规的 movq 指令只能以表示为32位补码数字的立即数作为源操作数
而 movabsq 指令能够以任意64位立即数值作为源操作数,且只能以寄存器为目的
MOV 指令只会更新目的操作数指定的那些寄存器字节或内存位置
注:常规的 movq 指令只能以表示为32位补码数字的立即数作为源操作数
而 movabsq 指令能够以任意64位立即数值作为源操作数,且只能以寄存器为目的 - 源操作数(source) 指定的值是一个立即数,存储在寄存器或内存中
- 目的操作数(destination) 指定的是寄存器或内存地址 注:x86-64增加了限制,两个操作数不能同时指向内存
将一个值从内存位置复制到另一个内存位置需要两条指令:
- 第一条 将源指令加载到寄存器中
- 第二条 将改寄存器值写入目的位置
注:movl 指令以寄存器作为目的时,会把该寄存器的高位4字节设置为0
原因是x86-64的惯例,为任何寄存器生成32位的指令都会把该寄存器的高位部分设置为0
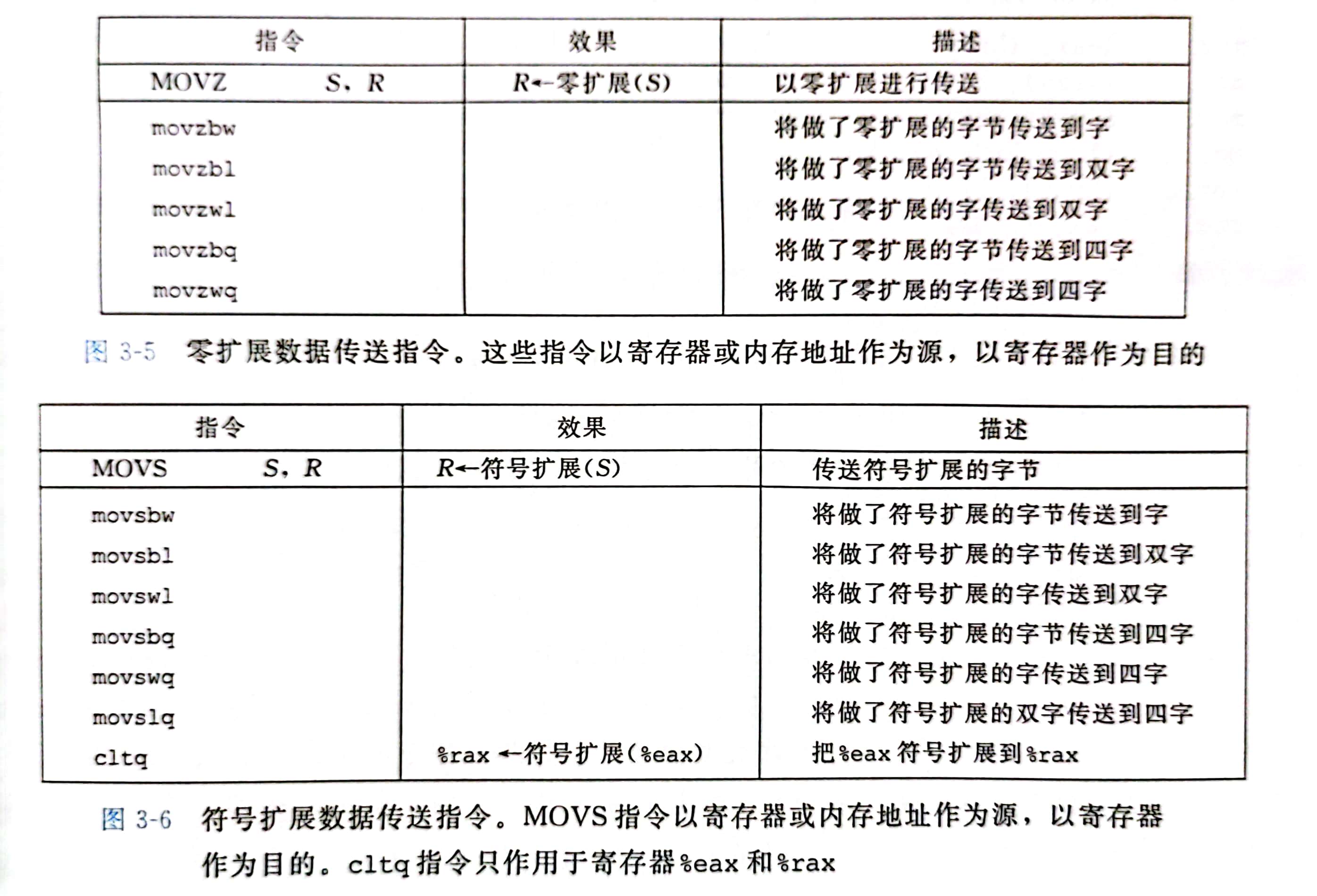 3-5,6是两类数据移动指令,将比较小的源值复制到交大的目的时使用
MOVZ 类总的指令把目的中剩余字节填充为0
MOVS 类中的指令通过符号拓展来填充,把源操作的最高位进行复制
3-5,6是两类数据移动指令,将比较小的源值复制到交大的目的时使用
MOVZ 类总的指令把目的中剩余字节填充为0
MOVS 类中的指令通过符号拓展来填充,把源操作的最高位进行复制
C语言中的指针其实就是地址,间接引用指针就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。 局部变量通常保存在寄存器中,而不是内存中。
压栈和弹栈
遵循 “先进后出”
通过 push 操作把数据压入栈中,通过 pop 操作删除数据
栈的属性 弹出的值永远是最近被压入而且仍在栈中的值
栈可以实现为一个数组,总是从数组的 一端 插入和删除数据, 这一端被称为栈顶。
在 x86-64 中,程序栈存放在内存中的某个区域。
栈向下增长,栈顶的元素的地址是所有栈元素地址中最低的,栈指针 %rsp 保存着栈顶元素的地址。
 将一个四字值压入栈中,首先要将栈指针减 8,然后将值写到新的栈顶地址
因此
将一个四字值压入栈中,首先要将栈指针减 8,然后将值写到新的栈顶地址
因此 pushq %rsp 等价于
subq $8,%rsp
movq %rbp,(%rsp)
区别在于 pushq 指令编码为 1byte,而上述需要 8byte
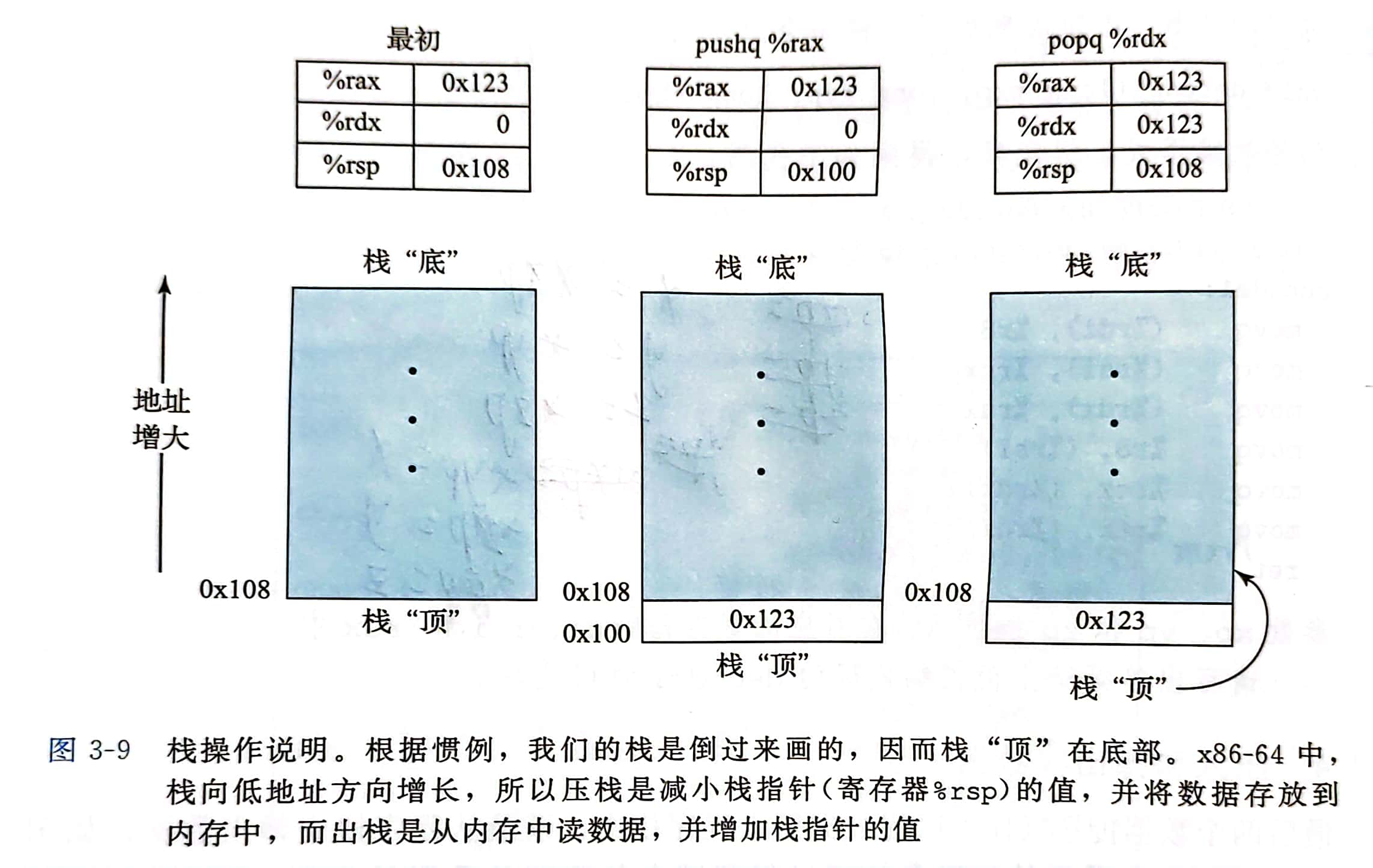 弹出一个四字的操作包括:从栈顶如初数据,将栈指针加 8
因此
弹出一个四字的操作包括:从栈顶如初数据,将栈指针加 8
因此 popq %rsp 等价于
movq (%rsp),%rax
addq $8,%rsp
注:3-9图三是执行完 pushq %rax 之后立即执行 popq %rdx 的效果 先从内存中读出值 0x123,再写到寄存器 %rdx 中,然后,寄存器 %rsp 的值将增加回到 0x108 而值 0x108 仍将保留在内存位置 0x100 中,直到被覆盖。
算数和逻辑操作
大部分操作都分成了指令类,这些指令类有各种带不同大小操作数的变种 (除 leaq) 这些操作被分为四组
- 加载有效地址
- 一元操作 有一个操作数
- 二元操作 有两个操作数
- 移位
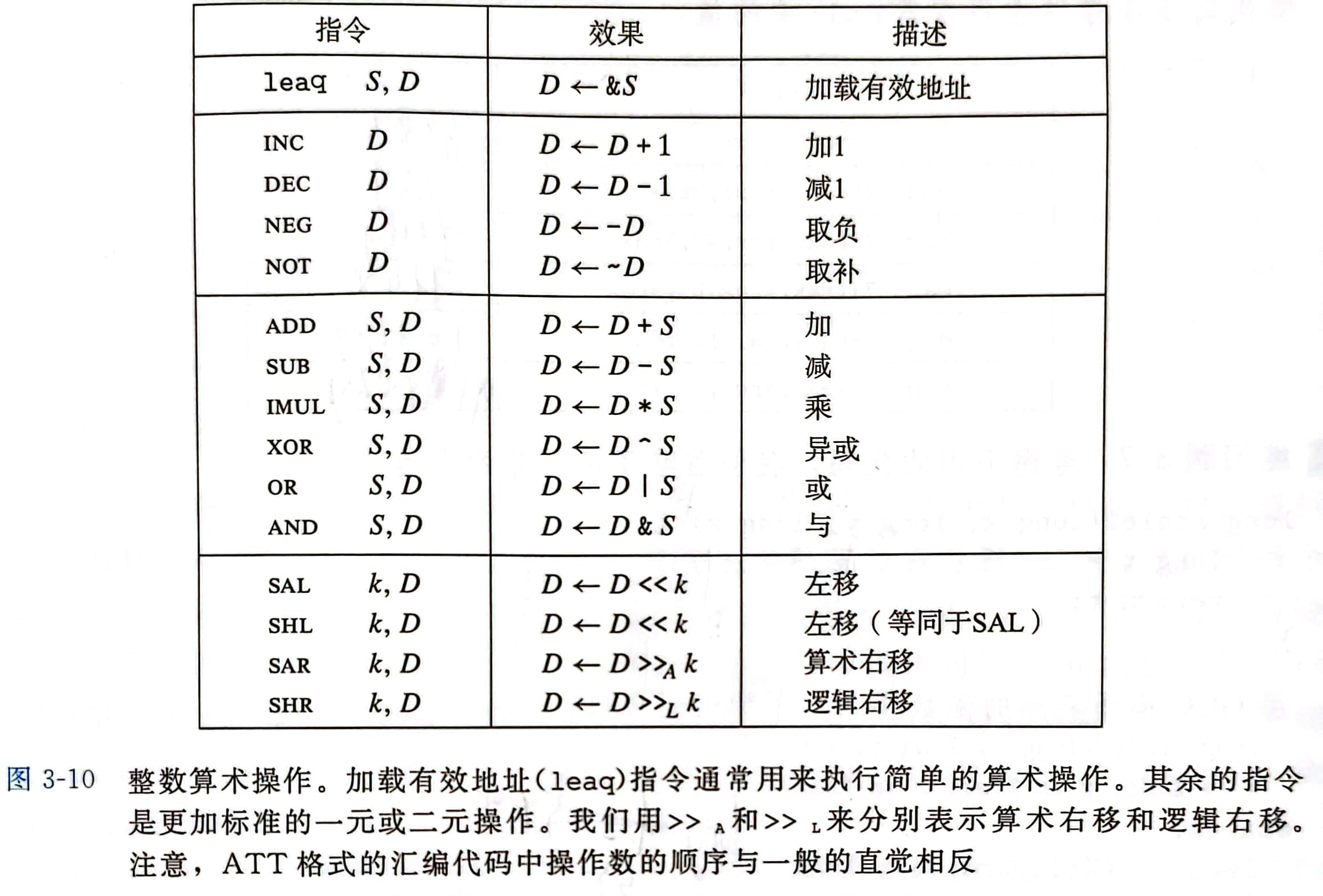
加载有效地址
表中第一组 加载有效地址 (leaq) 实际上是 movq 的变形,其目的操作数必须是一个寄存器 它的指令形式是从内存读取数据到寄存器,但实际上它根本没有引用内存 它的第一个操作数实际上是将有效地址写入到目的操作数
一元和二元操作
一元操作
表中第二组 只有一个操作数,既是源又是目的。 这个操作数可以是寄存器、也可以是内存位置
二元操作
表中第三组
其中,第二个操作数既是源又是目的
例如 sub %rax,%rdx ,是指从 %rdx 中减去 %rax
第一个操作数可以是立即数、寄存器或是内存位置 第二个操作数可以是寄存器或是内存位置 注:第二个操作数为内存地址时,处理器必须从内存读出值,执行操作,再把结果写回内存
移位操作
最后一组 先给出移位量,然后第二项给出的是要移位的数 可以进行算术右移或逻辑右移
移位量可以是一个立即数,或放在单字节寄存器 %cl 中
注:这些指令只允许以这个特定的寄存器作为操作数
在x86-64中,移位操作对 w 位长的数据值进行操作,位移量是由 %cl 寄存器的低 m 位决定的, 2^m = w ,高位会被忽略
例如: %cl 的值为 0xFF 时,指令 salb 会移 7 位, salw 会移 15 位, sall 会移 31 位,而 salq 会移 63 位
当 %cl : 0xFF =[1111 1111] 时
salb : 8个字节 (w=8) m=3 , 所以实际的移动长度为 [111] = 7 (实际移动位数为7)
salw : 16个字节 (w=16) m=4 , 所以实际的移动长度为 [1111] = 15 (实际移动位数为15)
sall : 32个字节 (w=31) m=5 , 所以实际的移动长度为 [1 1111] = 31 (实际移动位数为31)
salq : 64个字节 (w=63) m=6 , 所以实际的移动长度为 [11 1111] = 63 (实际移动位数为63)
sal 算术右移 (填符号)
shr 逻辑右移 (填0)
注:区分有符号数和无符号数
通常编译器产生的代码中,会用一个寄存器存放多个程序值,还会在寄存器间传送程序值 例:
long arith(long x,long y,long z)
{
long t1=x^y;
long t2=z*48;
long t3=t1&0x0F0F0F0F;
long t4=t2-t3;
return t4;
}
// x 在 %rdi , y 在 %rsi , z 在 %rdx
xorq %rsi, %rdi // 此处没有存放到新寄存器中,而是修改了x所在寄存器的值
leaq (%rdx,%rdx,2), %rax // 存放到寄存器 %rax 中, 3z
salq $4, %rax // 3z * 4
andl $252645135, %edi // 因为将异或的结果存放在x的寄存器中,所以用 %edi
subq %rdi, %rax // %rax -= %rdi
ret // %rax
// 表面上看上去有许多的程序变量,但实际上寄存器可能会反复使用
特殊的算数操作

控制
机器代码提供两种基本的低级机制来实现有条件的行为: 测试数据值,然后根据测试结果来改变控制流或者数据流
通常C语言中的语句和机器代码中的指令都是按照他们在程序中出现的次序,顺序执行
使用 jump 指令可以改变一组机器代码指令的执行顺序,jump 指令 指定控制应该被传递到程序的某个其他部分,可能依赖某个测试结果。
编译器必须构建在这种低级机制基础上的指令序列
条件码
CPU内有一组可以存储 单个位 的 条件码寄存器
用来描述最近的算数或逻辑操作的属性,可以检测这些寄存器来执行条件分支指令
常用条件码:
- CF : 进位标志 最近的操作使最高位产生了进位,可以用来检查无符号操作的溢出。
- ZF : 零标志 最近的操作得出的结果为 0
- SF : 符号标志 最近的操作得到的结果为负数
- OF : 溢出标志 最近的操作导致一个补码溢出 (正溢出或负溢出)
例:C表达式 t = a + b
CF (unsigned) t < (unsigned) a 无符号溢出
ZF t == 0 零
SF t < 0 负数
OF (a < 0 == b < 0) && (t < 0 != a < 0) 有符号溢出
对于图3-10,除 leaq 指令外,其余所有指令都会设置条件码
对于逻辑操作,进位标志和溢出标志设置为0
对于移位操作,进位标志设置为最后一个被移出的位,溢出标志设置为0
INC 和 DEC 指令会设置溢出和零标志,但不会改变进位标志
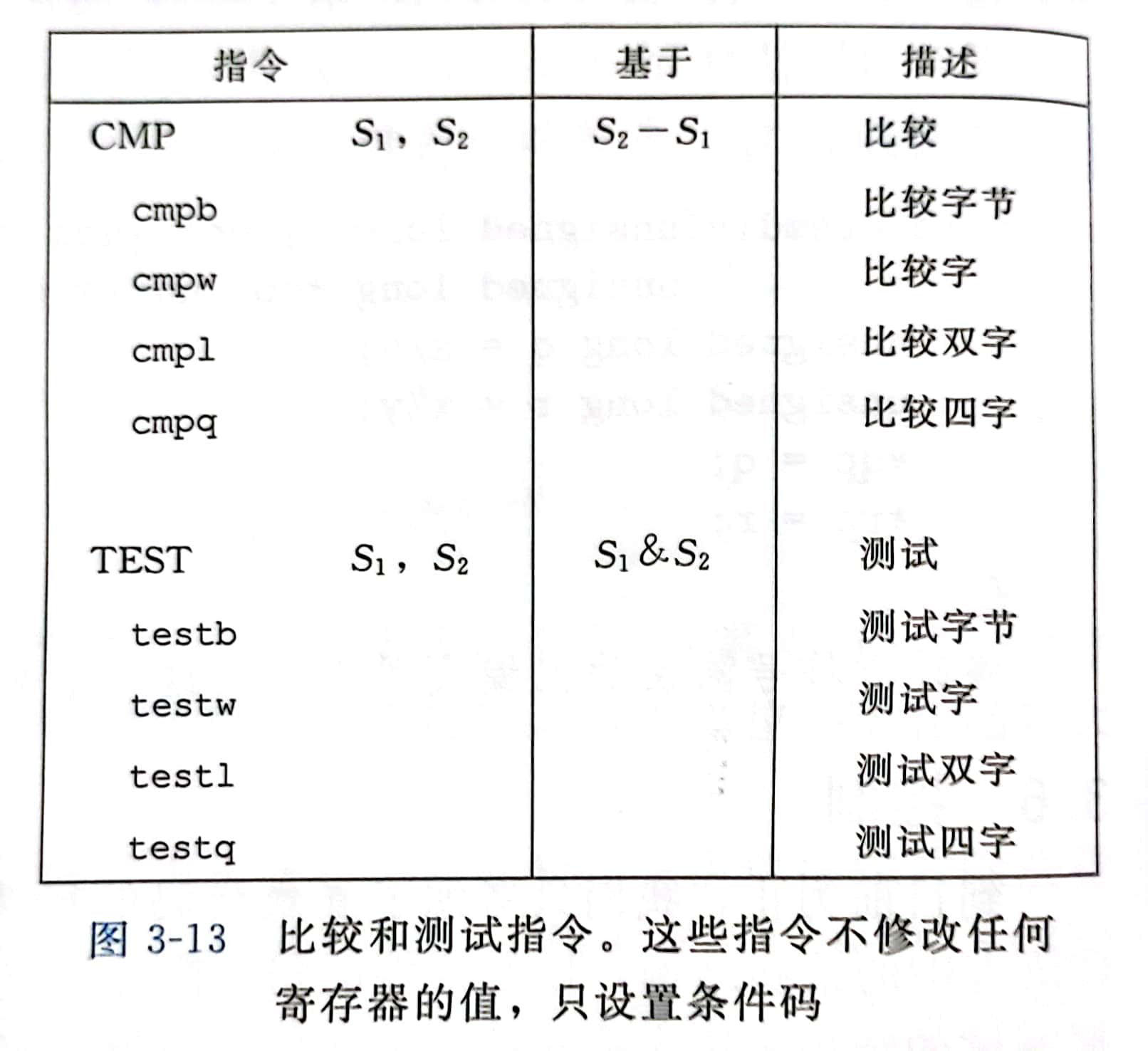
CMP 与 TEST 指令和 SUB 与 AND 指令的区别仅在于,前者只设置条件码而不更新目的寄存器
访问条件码
条件码常用的使用方法:
- SET指令 根据条件码的某种组合将一个字节设置为0或1
- 可以跳转到程序的某个其他部分
- 可以有条件的传送数据
SET指令
SET指令之间的区别在于它们考虑的条件码组合,不同后缀指明了它们所考虑的条件码的组合
这些后缀表示不同的条件而不是操作数的大小
例:setl 和 setb 指令表示 小于时设置 (set less) 和 低于时设置 (set below)
一条SET指令的目的操作数是低位单字节寄存器元素之一或是一个字节的内存位置
指令会将这个字节设置为 0 或 1
为了得到32位或64位的结果,必须对高位清零
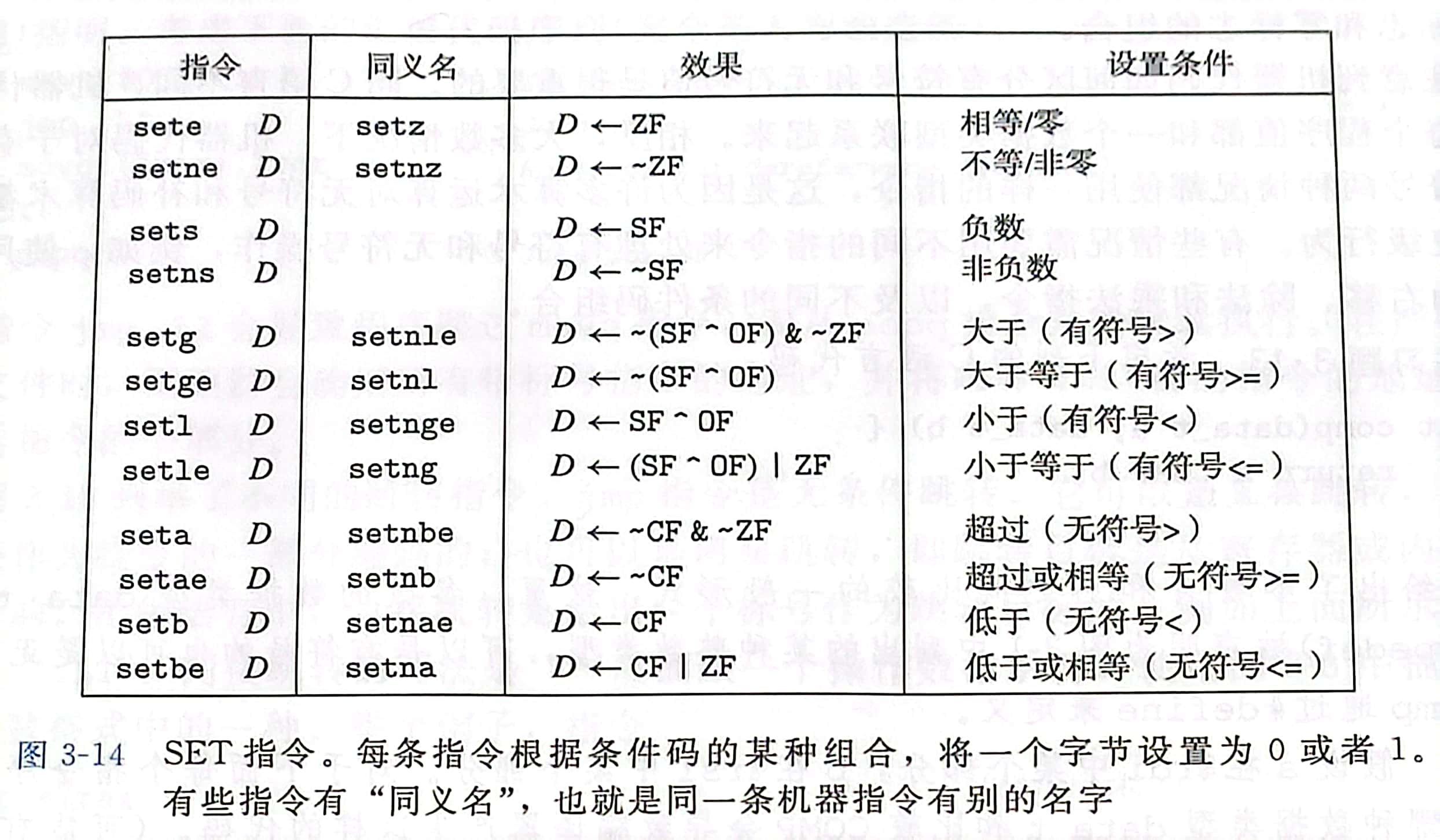
跳转指令
跳转指令会导致执行切换到程序中一个全新的位置,跳转目的地通常用一个标号 (label) 指明 同 Java 的 label,C 的 goto 在产生目标代码文件时,汇编器会确定所有带标号指令的地址,并将跳转目标 (目的指令的地址) 编码为跳转指令的一部分
jmp 指令可以直接跳转,即跳转目标是作为指令的一部分编码的;也可以间接跳转,即跳转目标是从寄存器或内存位置中读出,间接跳转的写法是 * 后面跟一个操作数指示符
 表中其他跳转都是有条件的,根据条件码的某种组合,进行执行,条件跳转只能是直接跳转
表中其他跳转都是有条件的,根据条件码的某种组合,进行执行,条件跳转只能是直接跳转
跳转指令的编码
最常用的都是 PC-relative
即,将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差作为编码,这些地址偏移量可以编码为1、2或4字节
第二种编码方法是 给出绝对地址,用4个字节直接指定目标
跳转指令提供了一种实现条件执行和几种不同循环结构的方式
用条件传送实现条件分支
实现条件操作的传统方法是通过使用 控制 的条件转移,但在现代处理器上,可能会非常低效
一种替代的策略是使用数据的条件转移,这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个。
只有在一些受限制的情况中,这种策略才可行,但是如果可行,就可以使用一条简单的 条件传送 指令来实现它
处理器通过使用 流水线 来获得高性能,在流水线中,一条指令要经过一系列的阶段,每个阶段执行所需操作的一小部分,然后通过重叠连续指令的步骤来获得高性能
例:在取一条指令的同时,执行它前面一条指令的算术运算。
要做到这一点,要求能够事先确定要执行的指令序列,这样才能保证流水线中充满待执行的指令。
当机器遇到条件跳转 (分支) 时,只有当分支条件完成求值之后,才能决定分支往哪边走
处理器采用非常精密的 分支预测逻辑 来猜测每条跳转指令是否会执行 (现代微处理器设计试图达到 90% 以上的成功率),只要猜测可靠,流水线中就会充满着指令;另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后的所有指令已做的工作,再开始用从正确位置处起始的指令去填充流水线,这将会浪费 15 ~ 30 个时钟周期。
下图列举了 x86-64 可用的条件传送指令
每条指令有两个操作数:源寄存器或内存地址S 和 目的寄存器R
源值可以从源寄存器或内存中读取,但之后再制定的条件满足时,才会被复制到目的寄存器中
源和目的的值可以是 16、32或64位,不支持单字节的条件传送
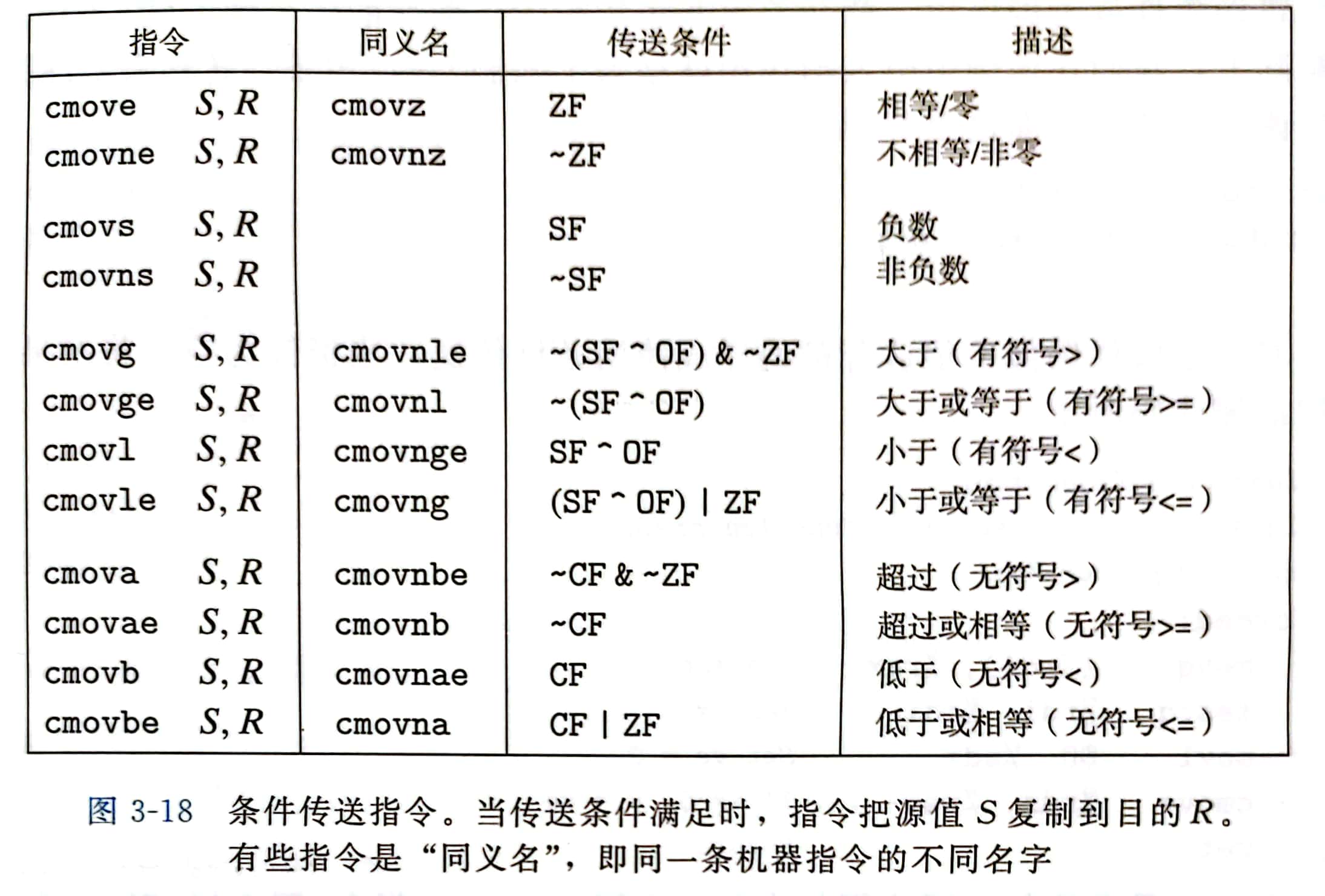
与条件跳转不同,处理器无需预测测试的结果就可以执行条件传送 处理器只是读源值,检查条件码,然后更新目的寄存器 或 保持不变
例:v = text-expr ? then-expr : else-expr
基于条件传送的代码:
v = then-expr;
ve = else-expr;
t = test-expr;
if (!t) {
v = ve;
}
只有当测试条件 t 不满足时,ve 的值才会被复制到 v 中
不是所有的条件表达式都可以用条件传送来编译。 且,无论测试结果如何, then-expr 和 else-expr 都会求值,这也就意味着这两个表达式中的任意一个产生条件错误或副作用,就会导致非法的行为。 注:类似 do-while 的模式
循环
do-while, while, for,汇编中没有相应的指令存在 可以用条件测试和跳转组合,实现循环的效果
switch语句
switch 语句可以根据一个整数索引值进行多重分支,它通过使用 跳转表 使得实现更加高效。跳转表是一个数组,表项 i 是一个代码段地址,这个代码段实现当开关索引值等于 i 时程序应该采取的动作。
用开关索引值执行一个跳转表内的数组引用,确定跳转指令的目标。
和一组很长的 if-else 语句相比,使用跳转表的优点是执行开关语句的时间与开关情况的数量无关,当开关情况比较多 (大于4个),且值的跨度范围比较小时,就会使用跳转表
注:略过大篇幅的描述 循环 和 switch 实现的汇编代码,原因是作者主要使用Java,且作者是懒狗
过程
过程是软件中一种很重要的抽象,它的形式多种多样:函数、方法、子例程、处理函数 等 它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能,然后可以在程序中不同地方调用这个方法
对 过程 的机器级支持:
假设 过程P 调用 过程Q,Q 执行后返回到 P,这些动作包括下面一个或多个机制
- 传递控制 在进入过程Q时,程序计数器 (PC) 必须被设置为 Q 的代码起始地址,然后在返回时,要把 PC 设置为 P 中调用 Q 后面那条指令的地址
- 传递数据 P 必须能向 Q 提供一个或多个参数,Q 必须能向 P 提供一个返回值
- 分配和释放内存 在开始时,Q 可能需要为局部变量分配空间,在返回前,必须释放这些空间
x86-64 的过程实现包括了一组特殊的指令和一些对及其资源使用的约定规则 它遵循了最低要求策略的方法,只实现上述机制中的每个过程所必需的那些
运行时栈
C 语言过程调用机制的关键特性在于,使用了栈数据结构提供的先进后出的内存管理原则 通过上例可看到,在P调用Q时,在Q返回前,P中的所有操作是被挂起的,在Q返回时,任何它分配的局部存储空间都可以被释放。 因此程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。当P调用Q时,控制和数据信息添加到栈尾,P返回时,这些信息会被释放。
前文讲过,x86-64 的栈向低地址方向增长,而栈指针 %rsp 指向栈顶元素,可以用 pushq 和 popq 压入或弹出数据。
将栈指针减少一个适当的量可以为没有指定初始值的数据在栈上分配空间,相反的,可以通过增加栈指针来释放空间
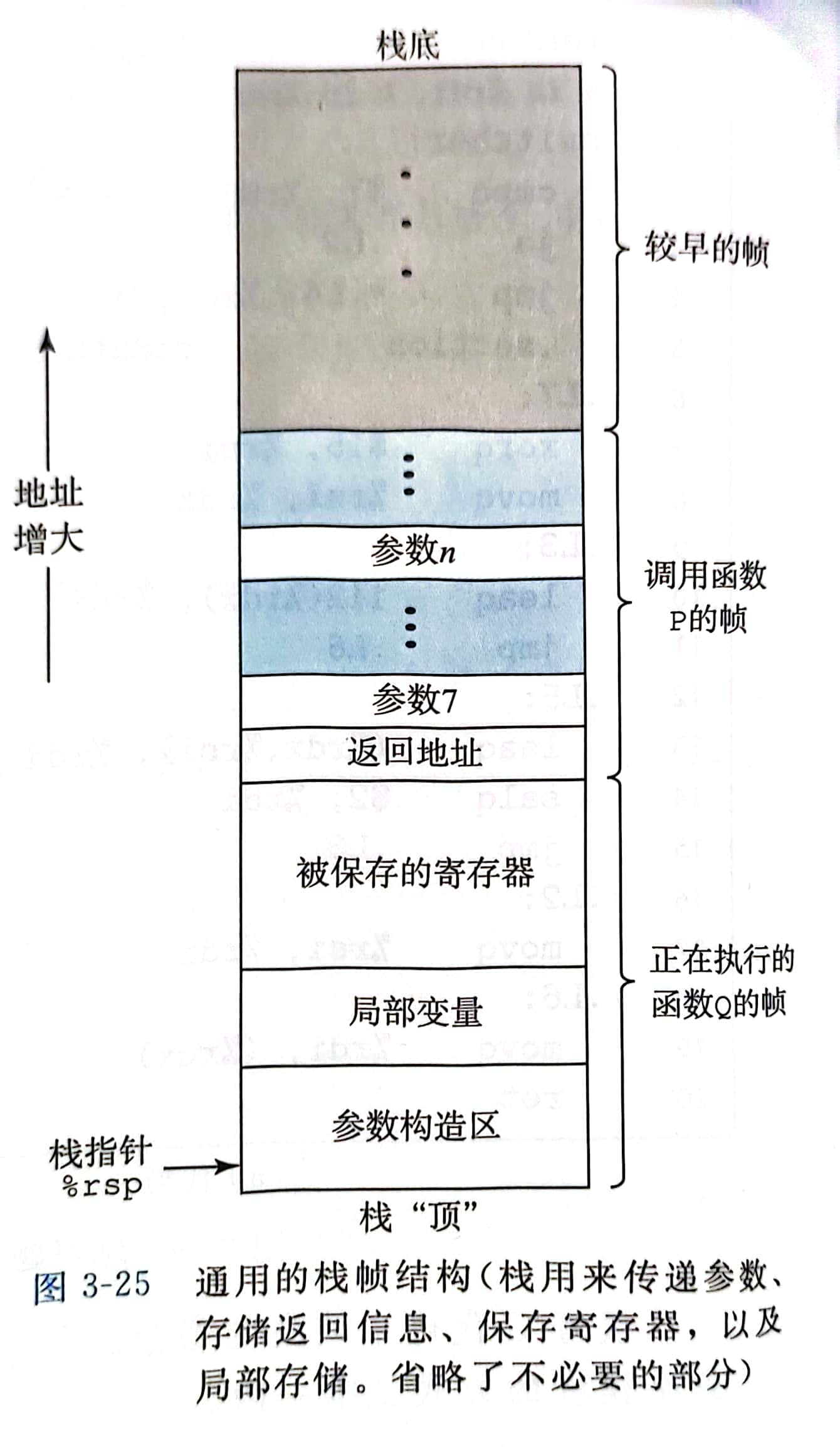 当x86-64 过程 需要的存储空间超出寄存器能够存放的大小事,就会在栈上分配空间,这部分被称为过程的
当x86-64 过程 需要的存储空间超出寄存器能够存放的大小事,就会在栈上分配空间,这部分被称为过程的 栈帧
当前正在执行的过程的帧总是在栈顶。
当过程P调用过程Q时,会把返回地址压入栈中,指明当Q返回时,要从P程序的哪个位置执行,我们把这个返回地址当做P的栈帧的一部分。
Q的代码会扩展当前栈的边界,分配它的栈帧所需的空间,在这个空间中,它可以保存寄存器的值,分配局部变量,为它调用的过程设置参数。
大多数过程的栈帧都是定长的,在过程的开始就分配好了,但是有些过程需要变长的帧 通过寄存器,过程P可以传递最多6个整数值(指针和整数),但是如果Q取药更多的参数,P可以在调用Q之前在自己的栈帧里存储好这些参数。
为了提高空间和时间效率,x86-64 过程只分配自己所需要的栈帧部分
实际上许多方法甚至根本不需要栈帧,当所有的局部变量都可以保存在寄存器中,而且该方法不会调用其他任何方法 (有时称之为 叶子过程,此时可以把过程调用看做 树结构)时,就可以这样处理。
转移控制
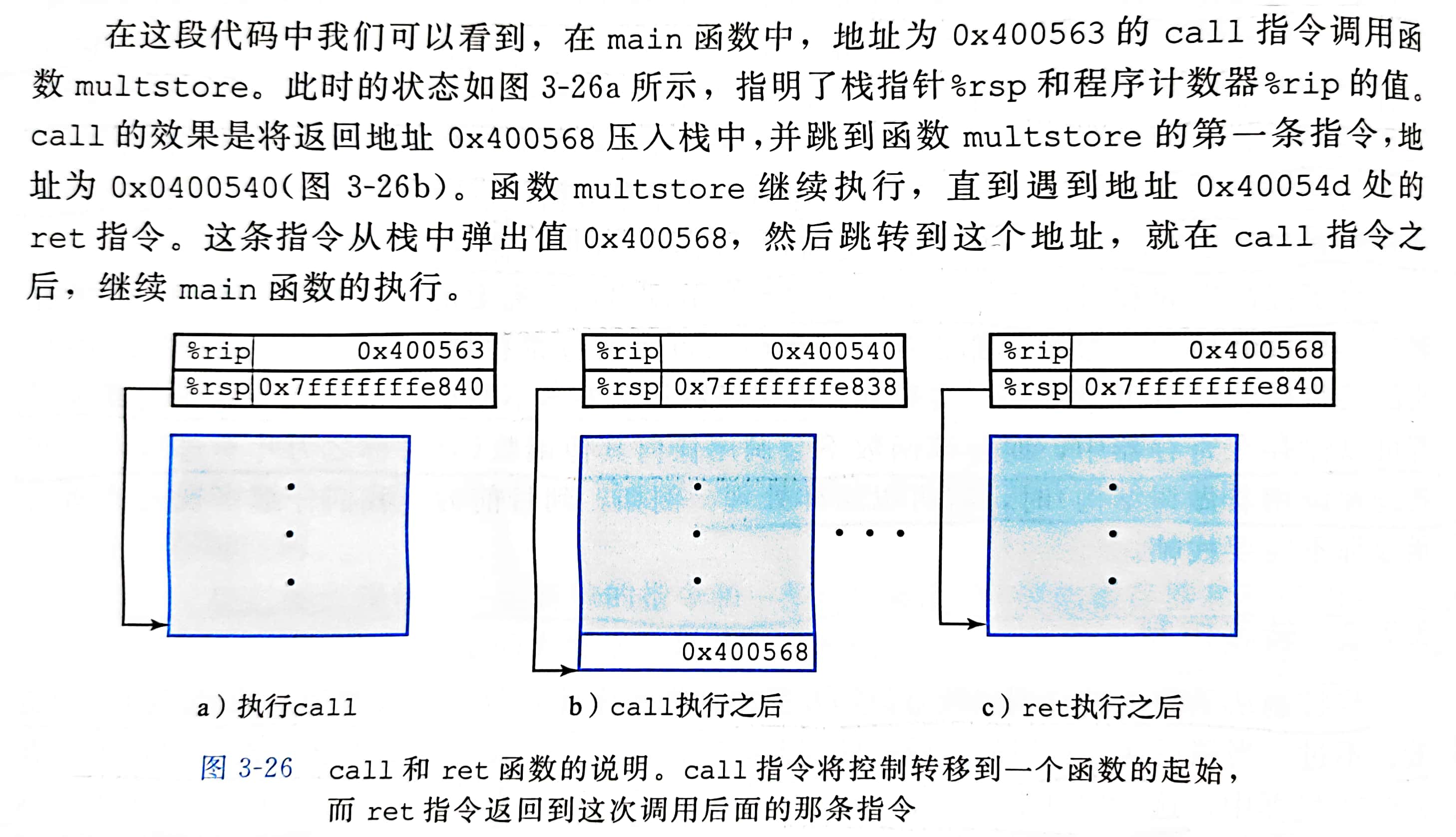
当控制从 函数P 转移到 函数Q 只需要简单的把 PC 设置为 Q 的代码的起始位置
从 Q 返回的时候,处理器必须记录好它在 P 中需要继续执行的代码位置
这个信息是用指令 call Q 调用 过程Q 来记录的
该指令会把地址A压入栈中,并将 PC 设置为 Q 的起始地址,压入栈的地址A被称为返回地址,是紧跟在 call 指令后面的那条指令的地址,对应的指令 ret 会从栈中弹出地址A,并把 PC 设置为 A
 call 指令有一个目标,即指明被调用 过程 起始的指令地址。同跳转一样,调用可以是直接的 (标号),也可以是间接的 (
call 指令有一个目标,即指明被调用 过程 起始的指令地址。同跳转一样,调用可以是直接的 (标号),也可以是间接的 ( * 后面跟一个操作数指令符)
数据传输
在 x86-64 中,大部分过程间的数据传送是通过寄存器实现的
可以通过寄存器最多传递 6 个整形参数,寄存器的使用是有特殊顺序的,寄存器使用的名字取决于要传递参数的数据类型的大小
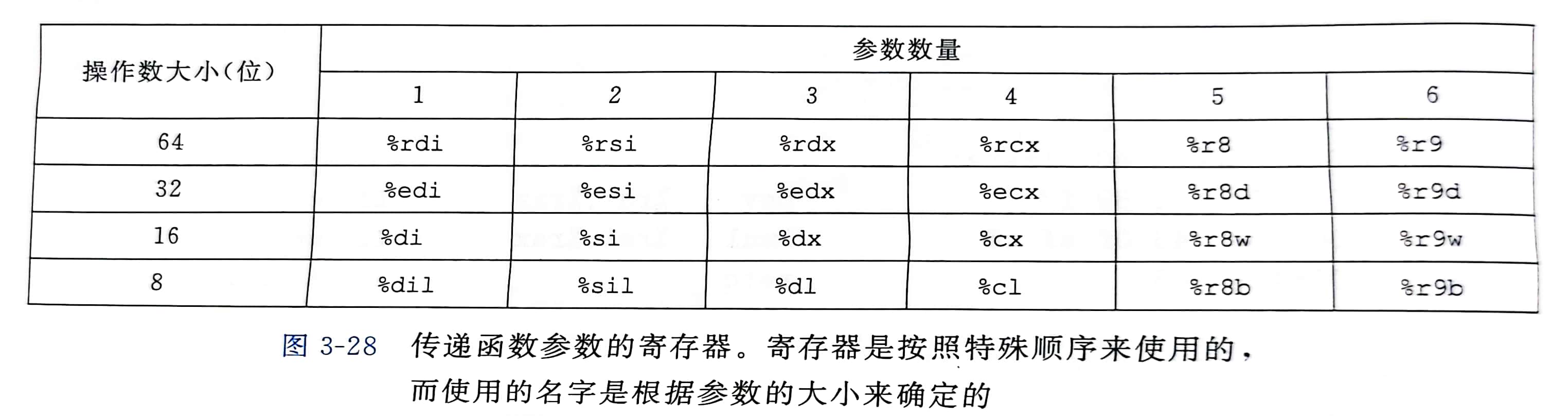
如果一个方法有大于 6 个整形参数,超出 6 个的部分就要通过栈来传递,1 ~ 6号复制到对应的寄存器,参数 7 ~ n 放到栈上,参数 7 位于栈顶
数组分配和访问
指针运算
C 语言 允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型的大小进行伸缩
如果 p 是一个指向类型为 T 的数据的指针,p 的值为 x_p,那么表达式 p + i 的值为 x_p + L * i,这里 L 是数据类型 T 的大小
单操作数操作符 & 和 * 可以产生指针和间接引用指针
例如:
对于某个实例的表达式 Expr,&Expr 是给出该实例地址的一个指针
对于某个地址表达式 AExpr,*AExpr 是给出该地址处的值
假设整型数组 E 的起始地址和整数索引 i 分别存放在寄存器 %rdx 和 %rcx 中,结果存放在 %eax 或寄存器 %rax 中

变长数组
历史上,C语言只支持大小在编译时就能确定的多维数组 C99 引入了动态数组,允许数组的长度是表达式
异质的数据结构
C语言提供了两种将不同类型的对象组合到一起创建数据类型的机制:struct 结构 ,将多个对象集合到一个单位中;union 联合,允许用几种不同的类型来引用一个对象
结构 struct
C语言的 struct 生命创建一个数据类型,将可能不同类型的对象聚合到一个对象中,用名字来引用结构的各个组成部分。
类似于数组的实现,结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第一个字节的地址。
注:类似于对象
联合 union
union 是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。您可以定义一个带有多成员的共用体,但是 任何时候只能有一个成员带有值 。union 提供了一种使用相同的内存位置 的有效方式。
分配给一个 union 对象的存储空间,至少要能容纳它的最大的数据成员(即一个 union 的存储空间至少要为其各个成员的数据类型中占字节数最大的一个成员的字节大小) 即一个 union 的总的大小等于它最大字段的大小。
一个 union 可以有多个不同类型的数据成员, 但在某一时刻只有一个成员有值(即只有一个成员是有效的)。 给 union 的某个成员赋值后,该 union 的其它成员就成未定义的状态。 如果我们事先知道一个数据结构中的两个不同字段的使用是互斥的,那么将这两个字段声明为 union 的一部分,会减少分配空间的总量。
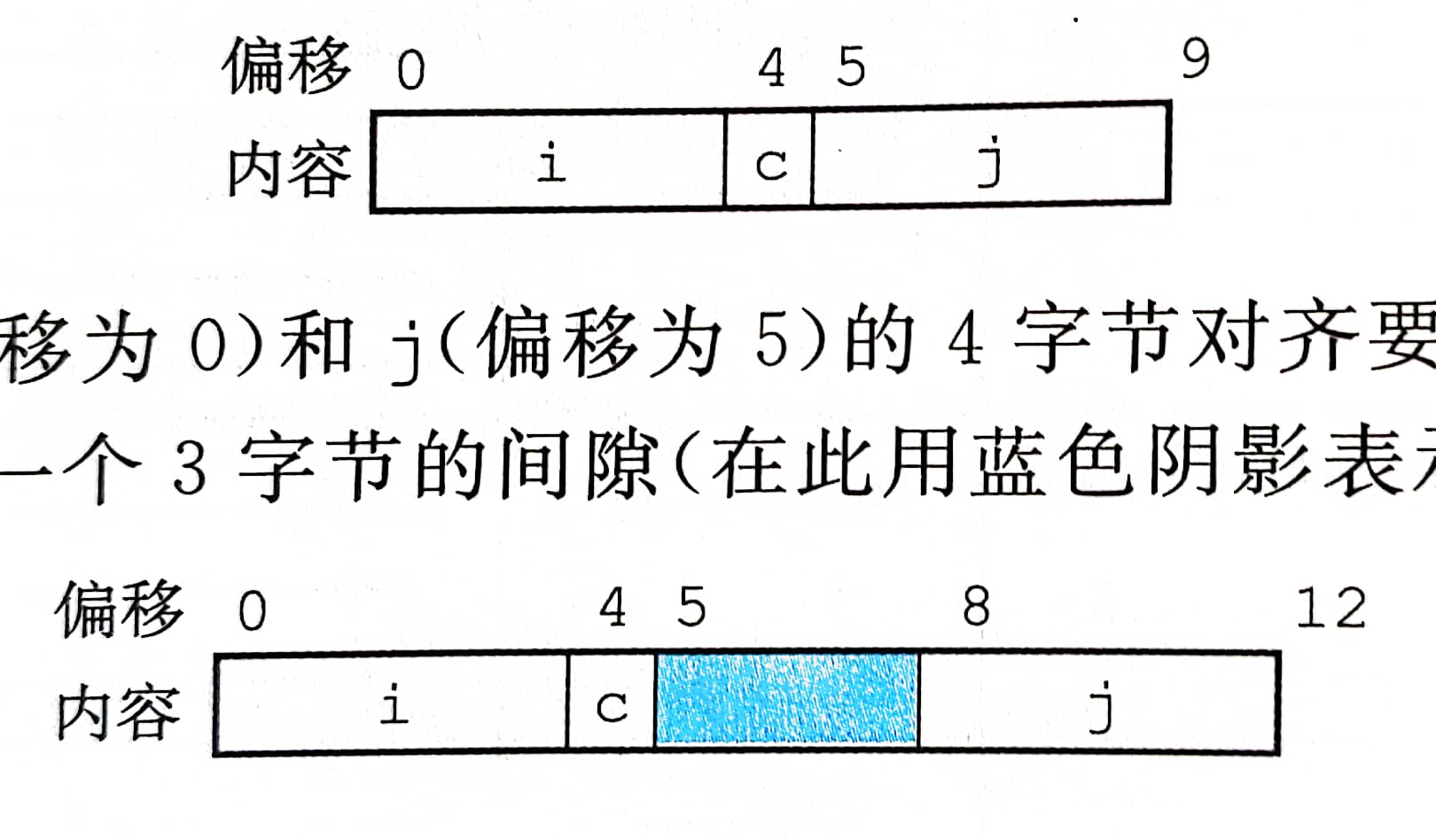
数据对齐
许多计算机系统对基本数据类型的合法地址做出了一些限制 要求某种类型对象的地址必须是某个值 (2、4、8) 的倍数 这种对齐限至简化了形成处理器和内存系统之间接口的硬件设计
对于包含结构的代码,编译器可能需要在字段的分配中插入见习,以保证每个结构元素都满足它的对齐要求

理解指针
- 每个指针都对应一个类型 表明该指针指向的是哪一类型的对象
- 每个指针都有一个值 这个值是某个指定类型对象的地址
- 指针用
&运算符创建 可以应用到任意赋值语句左边的表达式上,即汇编的lea指令 *操作符用于间接引用指针 其结果是一个值,它的类型与该指针的类型一致 间接引用是用内存引用来实现的,要么是存储到一个指定的地址,要么是从指定的地址读取- 数组与指针紧密联系
- 将指针从一种类型强制转换成另一种类型,只改变它的类型,而不改变它的值 (指向的地址)
- 指针也可以指向函数
// 定义方法fun
int fun(int x, int *p);
// 定义指针,指向方法fun
int (*fp)(int, int *);
fp = fun;
// 通过指针调用方法
int y = 1;
int rs = fp(3, &y);

内存越界引用和缓冲区溢出
C对数组引用不进行任何边界检查,因此对越界的数组元素的写操作会破坏存储在栈中的状态信息
一种特别常见的状态破坏称为缓冲区溢出。
常见:在栈中分配某个字符数组来保存一个字符串,但是字符串长度超出了为数组分配的空间
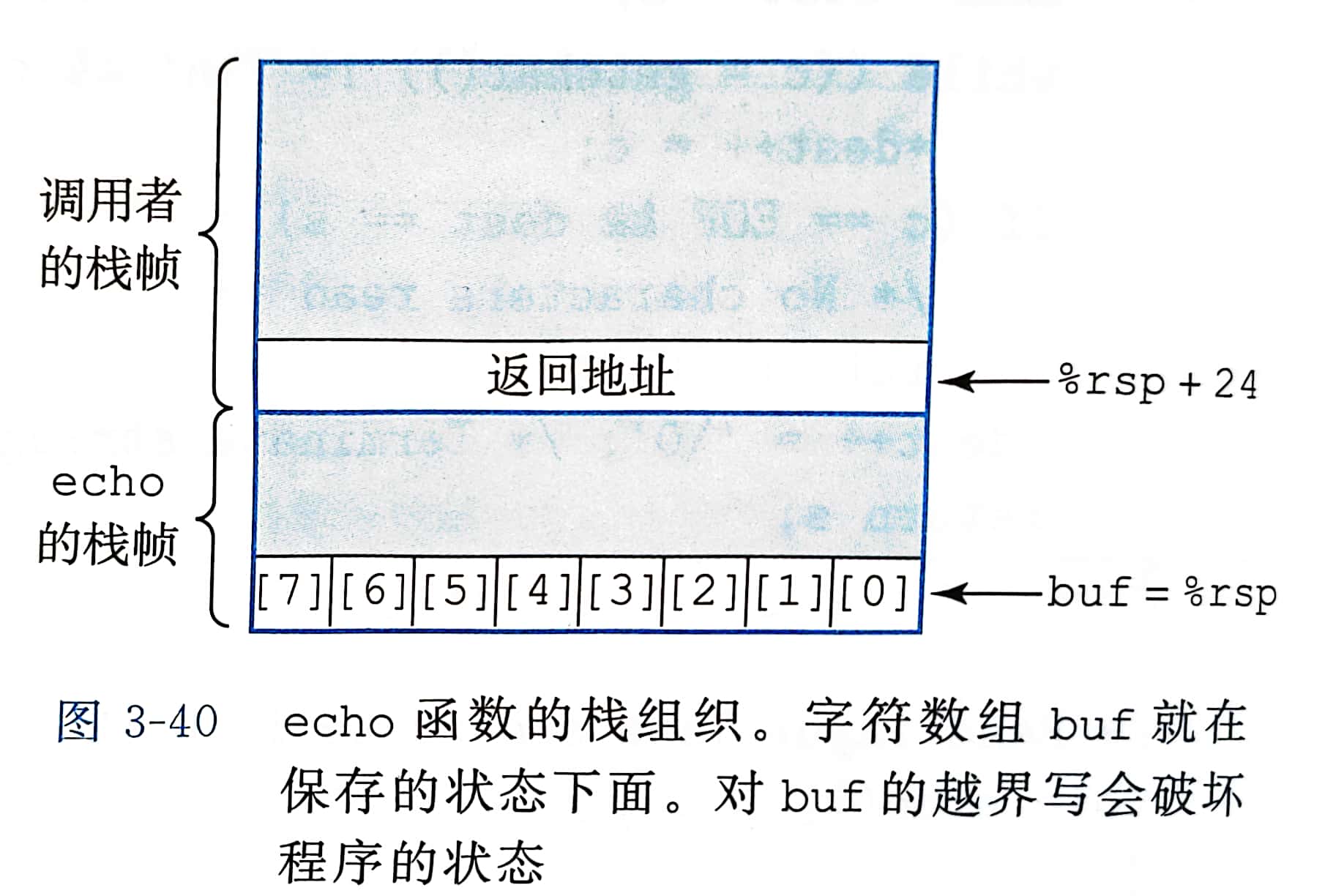
缓冲区溢出的一个更加致命的使用就是让程序执行他原本不愿意执行的方法。
通常,输入给程序一个字符串,这个字符串包含一些可执行的字节编码,称为攻击代码 另外,还有一些字节会用一个指向攻击代码的指针覆盖返回地址,那么执行ret的效果就是跳转到攻击代码
在一种攻击形势中,攻击代码会使用系统调用启动一个 shell 程序,给攻击者提供一组操作系统函数 在另一种攻击形势中,攻击代码会执行一些未授权的任务修复对栈的破坏,然后第二次执行 ret 指令,表面上正常返回到调用者
知名病毒:
- 蠕虫病毒 蠕虫可以自己运行,并且能够将自己的等效副本传播到其他机器
结论:任何到外部环境的接口,都应该进行检查,这样,外部代理的行为才不会导致系统出现错误
注:病毒能经自己添加到包括操作系统在内的其他程序之中,但它不能独立运行。
对抗缓冲区溢出攻击
栈随机化
对于所有运行同样程序的和操作系统版本的系统来说,栈的位置是相当固定的
如果攻击者可以确定一个常见的服务器所使用的栈空间,就可以设计一个在许多机器上都能实施的攻击
许多系统容易受到同一种病毒的攻击,这种现象常被称作 安全单一化
栈随机化的思想使得栈的位置在程序每次运行时都有变化,实现的方式是:在程序开始时,在栈上分配一段 0 ~ n 字节之间的随机大小的空间
在Linux系统中,栈随机化已经变成了标准的行为。
它是更大的一类技术中的一种,被称为 地址空间布局随机化,或简称 ASLR
采用ASLR,每次运行时程序的不同部分,包括程序代码、库代码、栈、全局变量和对数据,都会被加载到内存的不同区域
但,攻击者可以反复的用不同的地址进行攻击
一种常见的把戏就是在实际的攻击代码前插入很长的一段 nop (读作 no op,no operation的缩写)
执行这种指令除了对 PC 加一,使之指向下一条指令以外,没有任何效果
只要攻击者能够猜中这段序列中的某个地址,程序就会经过这个序列,到达攻击代码
这个序列常用的术语是空操作雪橇 (nop sled),意思是程序会 “滑过” 这个序列
如果我们建立一个 256字节 的 nop sled,那么枚举 2^15 = 32768个起始地址,就能破解 n = 2^23 的随机化
栈破坏检测
计算机的第二道防线是能够检测到何时栈已经被破坏
栈保护者机制,其思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的 金丝雀值 (canary),也称为哨兵值,是在程序每次运行时随机产生的
在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常终止。
xorq %fs:40, %rax
指令参数 %fs:40 指明金丝雀值是用 段寻址 ,从内存中读入的,段寻址机制可以追溯到 80286 的寻址,而现代系统上运行的程序中已经很少见到了。
限制可执行代码区域
第三种方法是限制哪些内存区域可以存放可执行代码
在典型的程序中,只有保存编译器产生的代码的那部分内存才需要是客户字形的,其他部分可以被限制为只读和只写
虚拟内存空间在逻辑上被分成了 页 (page),典型的每页是 2048 或者 4096 字节
系统允许控制三种访问形式:读 (从内存读数据)、写 (写数据到内存)、执行 (将内存的内容看做机器级代码)
以前,x86体系结构将读和执行访问控制合并成了一个 1位的标志,这样任何被标记为可读的页也是可执行的
栈必须可读又可写,因而栈上的字节也都是可执行的。
现在,内存保护引入了 NX (No-Execute) 位,将读和执行访问模式分开
及时编译 技术为解释语言 (Java) 编写的程序动态地产生代码,以提高执行性能
是否能够将可执行代码限制在由编译器在创建原始程序时产生的那个部分中,取决于语言和操作系统
支持变长栈帧
x86-64 使用 %rbp 作为 帧指针 (frame pointer) 或 基指针 (base pointer)
在较早版本的 x86 代码中,每个函数调用都使用了帧指针 现在,只在栈帧长可变的情况下使用
浮点代码
处理器的浮点体系结构包括多个方面,会影响对浮点数据操作的程序如何被映射到机器上,包括:
- 如何存储和访问浮点数值 通常是通过某种寄存器方式来完成
- 对浮点数据操作的指令
- 向函数传递浮点参数和从函数返回浮点数结果的规则
- 函数调用过程中保存寄存器的规则
Intel 和 AMD 都引入了 持续数代 的 媒体 指令
这些指令本意是允许多个操作以并行模式执行,称为 单指令多数据 或 SIMD
这些拓展指令集经过长足的发展,名字经过了一系列大的修改,从 MMX 到 SSE,以及最新的 AVX (Advance Vector Extension 高级向量拓展)
每个拓展都是管理寄存器组中的数据,这些寄存器组在 MMX 中称为 MM 寄存器,SSE 中称为 XMM 寄存器,而在 AVX 中称为 YMM 寄存器
MM寄存器是64位,XMM是128位,YMM是256位的
所以每个YMM寄存器可以存放8个32位或4个64位值,这些值可以是整数,也可以是浮点数

浮点传送和转换操作
引用内存的指令是标量指令,意味着它们只对单个而不是一组封装好的数据值进行操作
数据要么保存在内存中,要么保存在 XMM 寄存器中
内存引用的指定方式与整数 MOV 指令一样,包括偏移量、基址寄存器、变址寄存器和伸缩因子的所有可能的组合
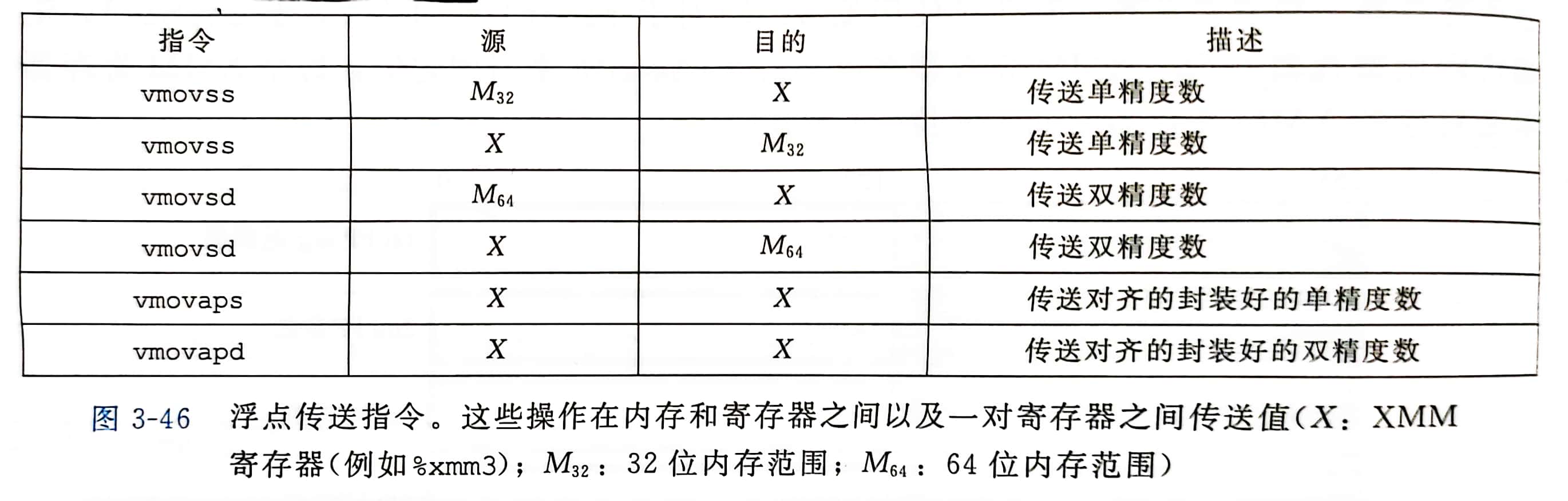 编译器只用标量传送操作从内存传送数据到 XMM 寄存器 或从 XMM 寄存器传送数据到内存
在两个 XMM 寄存器之间传送数据,编译器会用 vmovaps 传送单镜度数,用 vmovapd 传送双镜度数
注:指令名字中的字母 a,表示 aligned (对齐的)
编译器只用标量传送操作从内存传送数据到 XMM 寄存器 或从 XMM 寄存器传送数据到内存
在两个 XMM 寄存器之间传送数据,编译器会用 vmovaps 传送单镜度数,用 vmovapd 传送双镜度数
注:指令名字中的字母 a,表示 aligned (对齐的)
把浮点值转换成整数时,指令会执行截断,把值向 0 进行舍入,这是C和大多数其他语言的要求
过程中的浮点代码
在x86-64中,XMM寄存器用来向函数传递浮点参数,以及从函数返回浮点值
- XMM 寄存器
%xmm0 ~ %xmm7最多可以传递 8 个浮点参数,可以通过栈传递额外的浮点参数 - 函数使用寄存器
%xmm0来返回浮点值 - 所有的XMM寄存器都是调用者保存的没被调用者可以不经保存就覆盖这些寄存器中的任意一个
当函数包含指针、整数、浮点数混合时的参数时,指针和整数通过寄存器传递,而浮点值通过 XMM 寄存器传递
浮点运算操作
第一个源操作数 S1 可以是一个 XMM寄存器 或一个内存位置
第二个源操作数和目的操作数都必须是 XMM寄存器
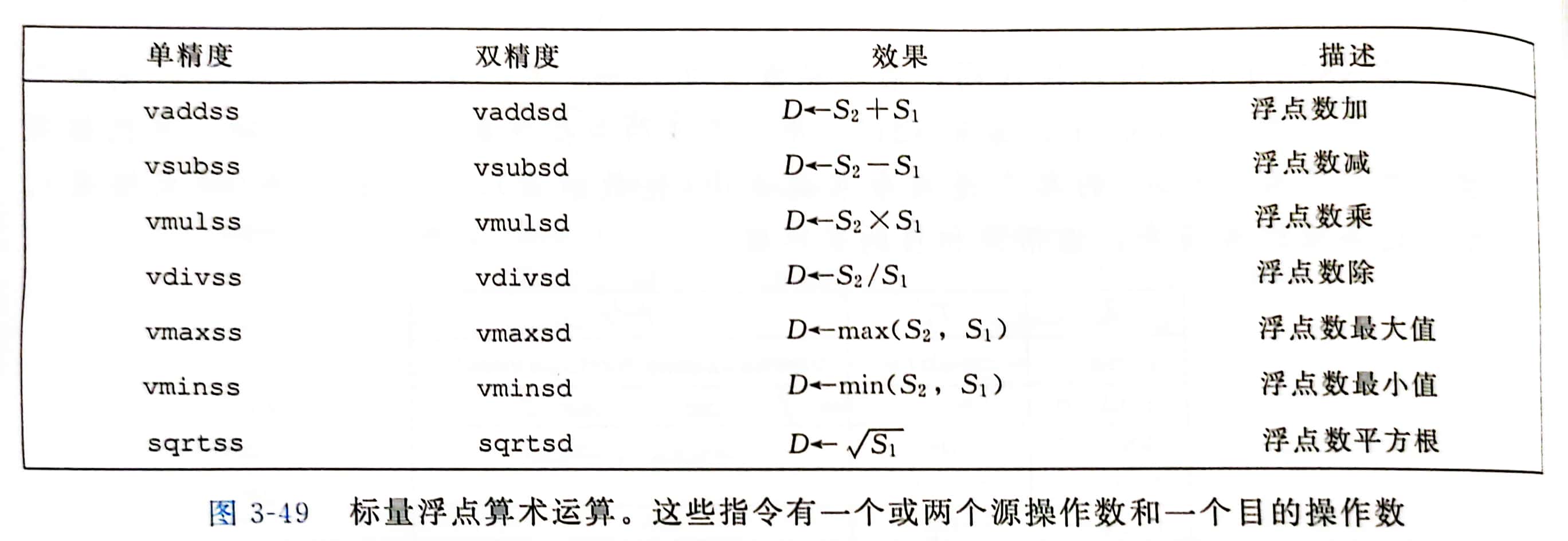
AVX浮点操作不能以 立即数 作为操作数
浮点比较操作
 以上指令类似于CMP指令
参数S2必须在 XMM 寄存器中,而 S1 可以在 XMM 寄存器中,也可以在内存中
浮点比较指令会设置三个条件码:
以上指令类似于CMP指令
参数S2必须在 XMM 寄存器中,而 S1 可以在 XMM 寄存器中,也可以在内存中
浮点比较指令会设置三个条件码:
- 零标志位 ZF
- 进位标志位 CF
- 奇偶标志位 PF 对于整数比较,当最近的一次算数或逻辑运算产生的值的最低位字节是偶校验的,那么就会设置这个标志位 对于浮点比较,两个数只要有一个是NaN时,就会设置该位
条件码设置条件:
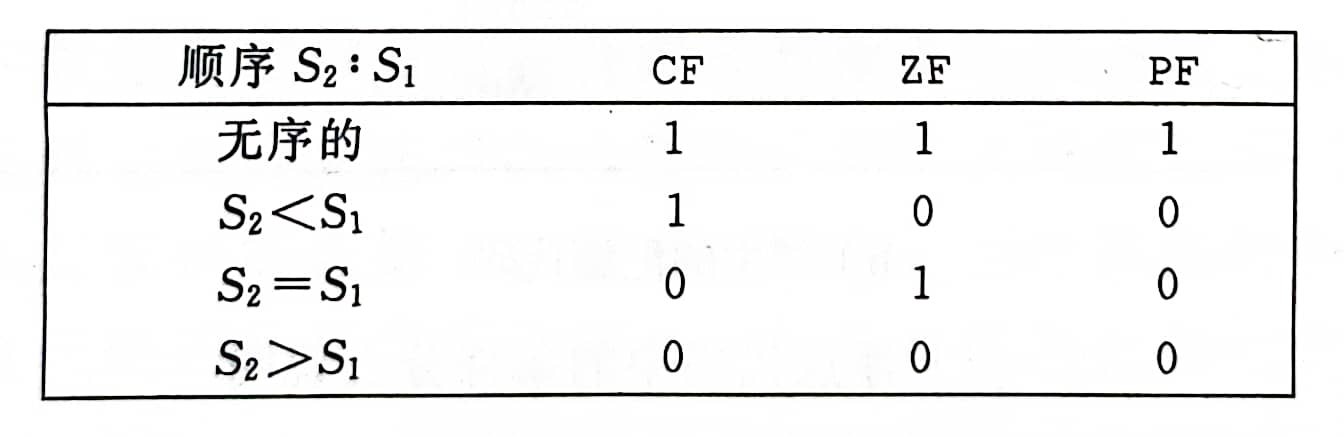
当任意操作数为NaN时,就会出现无序的情况,可以通过奇偶标志位发现这种情况
章节小结
编译C++与编译C非常类似。实际上,C++的早期实现就只是简单地执行了从C++到C的源到源的转换,并对结果运行C编译器,产生目标代码。 C++的对象用结构来表示,类似C的struct,C++的方法是用指向方法的实现代码的指针来表示的 Java的实现方式完全不同。 Java的目标代码是一种特殊的二进制表示,称为Java字节代码 (字节码)。 这种代码可以看成是虚拟机的机器级程序,这种机器并不是直接用硬件实现的,而是用软件解释器处理字节码,模拟虚拟机的行为。 另外,有一种称为 及时编译 的方法,动态地将字节码序列翻译成机器指令。 用字节码作为程序的低级表示,有点事相同的代码可以在许多不同的机器上执行,而本章的机器代码只能在 x86-64 机器上运行。

